

(Español) Author Profiling en textos rusos en RusProfiling (PAN@FIRE 2017)
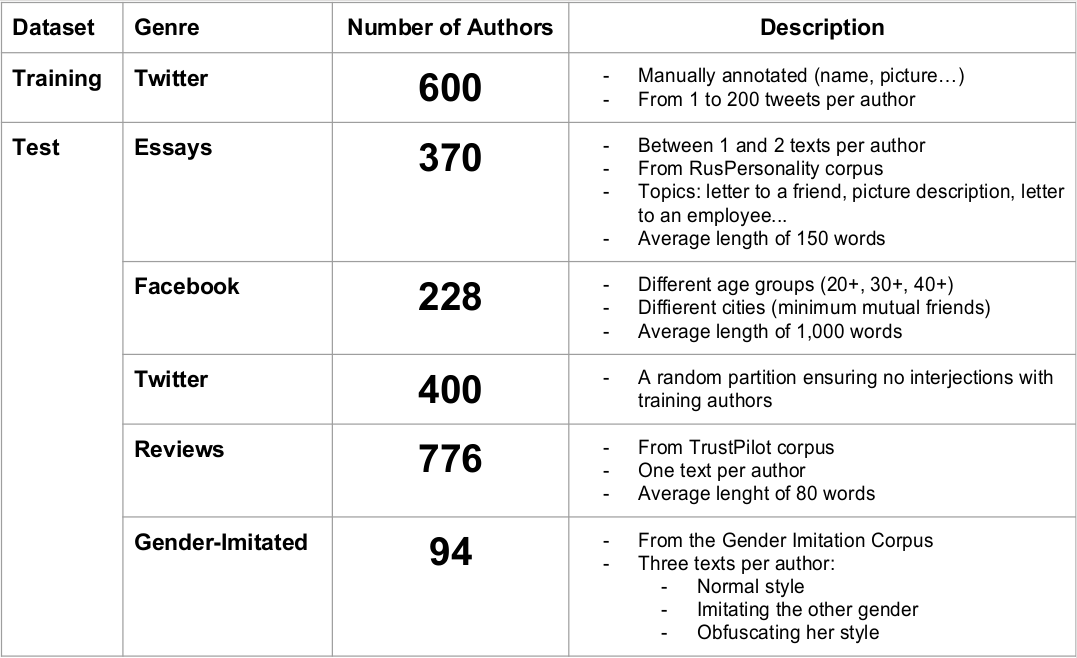
 La semana pasada presentamos la tarea RusProfiling en la conferencia FIRE en Bangalore, India, internacionalizando aún más el laboratorio PAN. El objeto de la tarea ha sido identificar el sexo de escritores anónimos, pero desde una perspectiva cross-medio (cross-genre). Es decir, dados textos de entrenamiento obtenidos de un medio como Twitter, se debía proceder a identificar el sexo de autores anónimos de Facebook, ensayos, revisiones, Twitter, y como novedad con respecto a cualquier otra tarea, textos donde el autor imitaba entre otras cosas el estilo del sexo contrario. En la siguiente tabla se detalla cada uno de estos corpus:
La semana pasada presentamos la tarea RusProfiling en la conferencia FIRE en Bangalore, India, internacionalizando aún más el laboratorio PAN. El objeto de la tarea ha sido identificar el sexo de escritores anónimos, pero desde una perspectiva cross-medio (cross-genre). Es decir, dados textos de entrenamiento obtenidos de un medio como Twitter, se debía proceder a identificar el sexo de autores anónimos de Facebook, ensayos, revisiones, Twitter, y como novedad con respecto a cualquier otra tarea, textos donde el autor imitaba entre otras cosas el estilo del sexo contrario. En la siguiente tabla se detalla cada uno de estos corpus:
Hemos tenido 5 participantes que han enviado hasta un total de 93 ejecuciones. Algunos de los principales hallazgos han sido los siguientes:
- A diferencia de otras tareas de author profiling, en este caso las técnicas de deep learning han obtenido prácticamente los mejores resultados, especialmente en los corpus de ensayos y textos imitados.
- Los mejores resultados no se han obtenido en Twitter, sino en Facebook.
- Los peores resultados se han obtenido en revisiones.
En la siguiente tabla se resume el estado del arte de la tarea RusProfiling para cada uno de los corpus. En ella, se muestra el mejor resultado obtenido por los participantes, así como una segunda línea con nuestro método LDR, recientemente rebautizado como LDSE (Low Dimensionality Statistical Embedding), utilizado como baseline “dura” en todas las tareas que organizamos.

Para más información sobre la tarea y los resultados, se recomienda consultar:
2 Comments
Submit a Comment
My presentations
") Profiling Irony and Stereotype Spreaders on Twitter (IROSTEREO)
Profiling Irony and Stereotype Spreaders on Twitter (IROSTEREO)
Date: Tue May 9 16:35
This is a very timely and relevant task given the amount of hate content generated on the social media today.
We recently annotated 75000 tweets with one of 4 labels (Hate, Objectionable, Provocative and Normal) for a research team.
We provide data collection and annotation services, please do contact us https://www.xsaras.com